Console flow
URL:https://console.gmicloud.ai/user-console/ie/deployments
The Deployments page is where you provision and manage dedicated endpoints.
- Create Deployment (top-right): launches the wizard for selecting a model, region, GPU type, and scaling.
- Once running, the page lists each endpoint with its status, model, region, replica count, and per-deployment actions.
You haven’t deployed any models yet Deploy an open source model from the Model Library.Featured shortcut cards offer one-click starts for popular models like Gemini 3.5 Flash, MiMo-V2.5-Pro, GPT-5.5, and DeepSeek-V4-Pro. The Explore more link jumps to the full model catalog. For per-model API docs, see the Text catalog.
Create your Dedicated Inference Endpoint
Deploy a dedicated inference model
Select a model from the list. Click the “Dedicated” button to start deployment: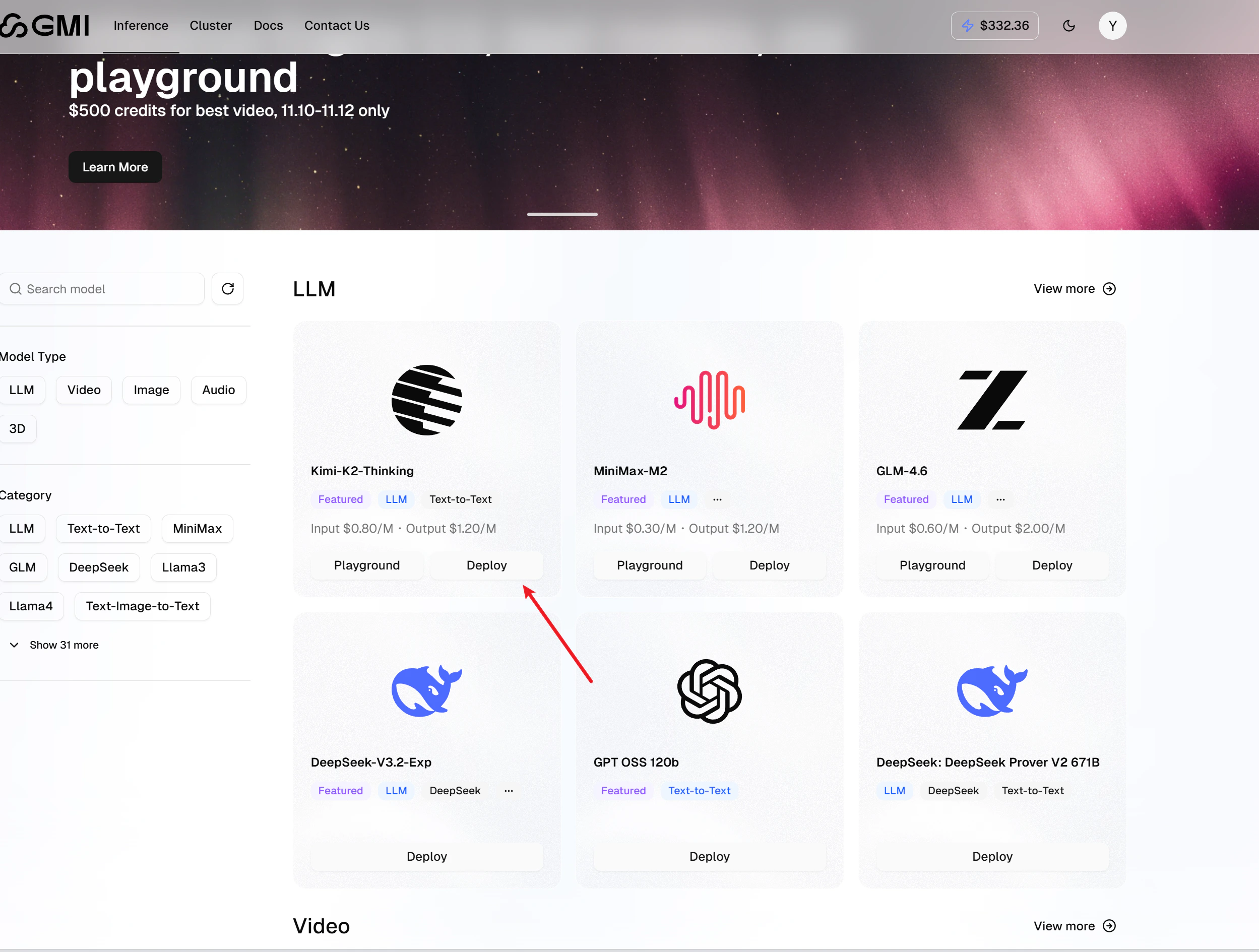
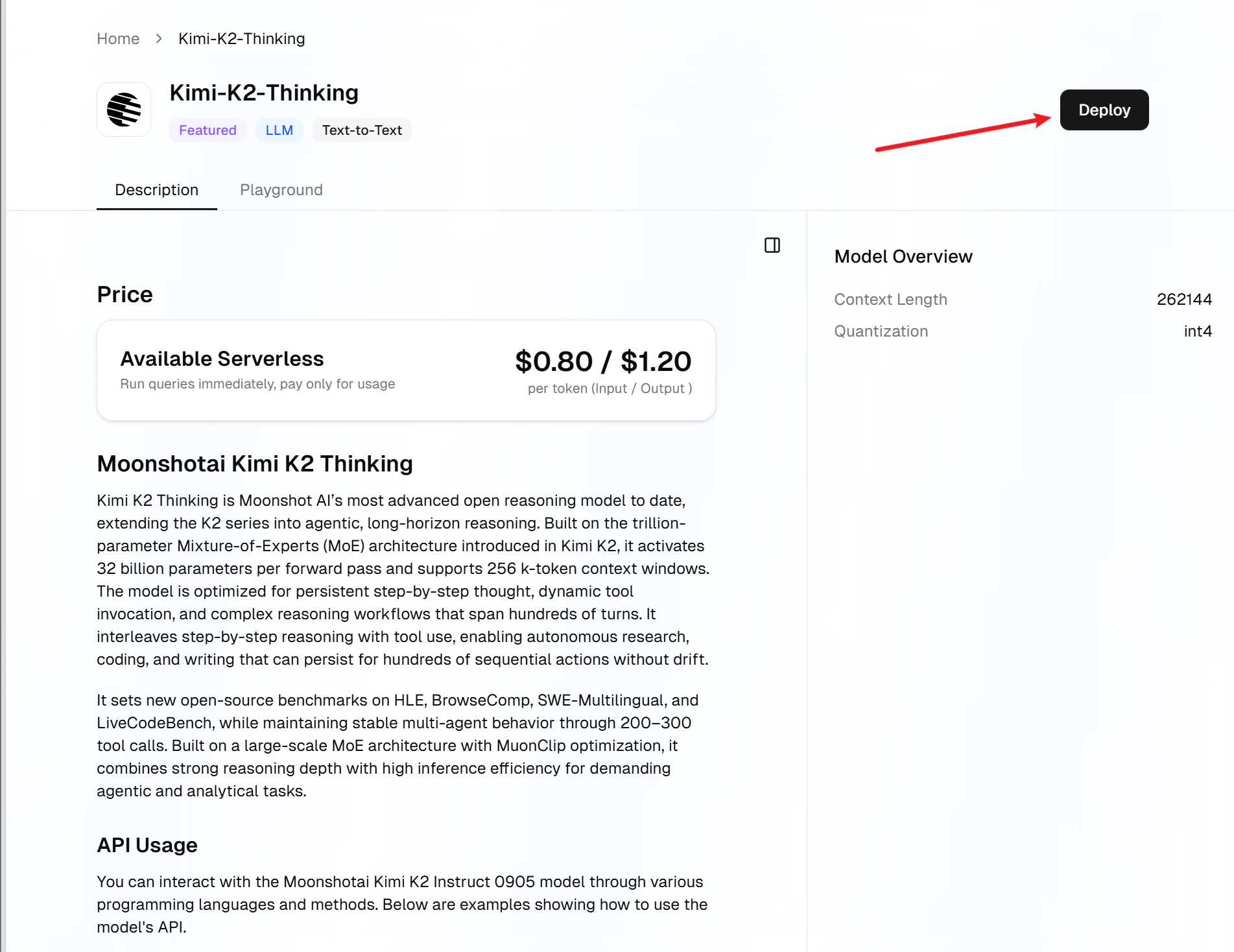
Review Configurations
Confirm your GPU type, deployment name, auto-scaling policy, and other system configurations: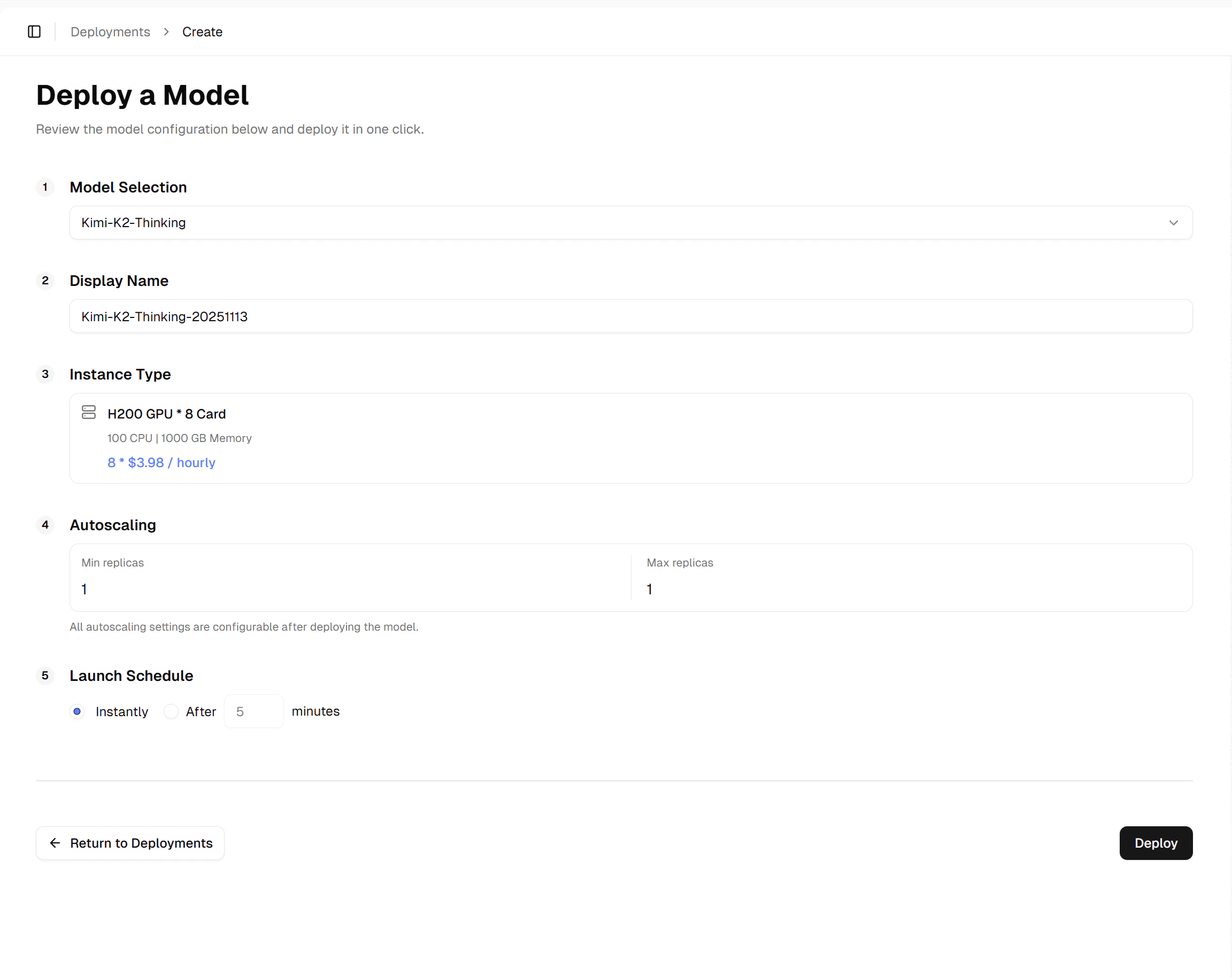
View Deployment Status
To view your deployment status click the “Deployment” tab on the top right.
You will only be billed for the period of time in “Running” status.
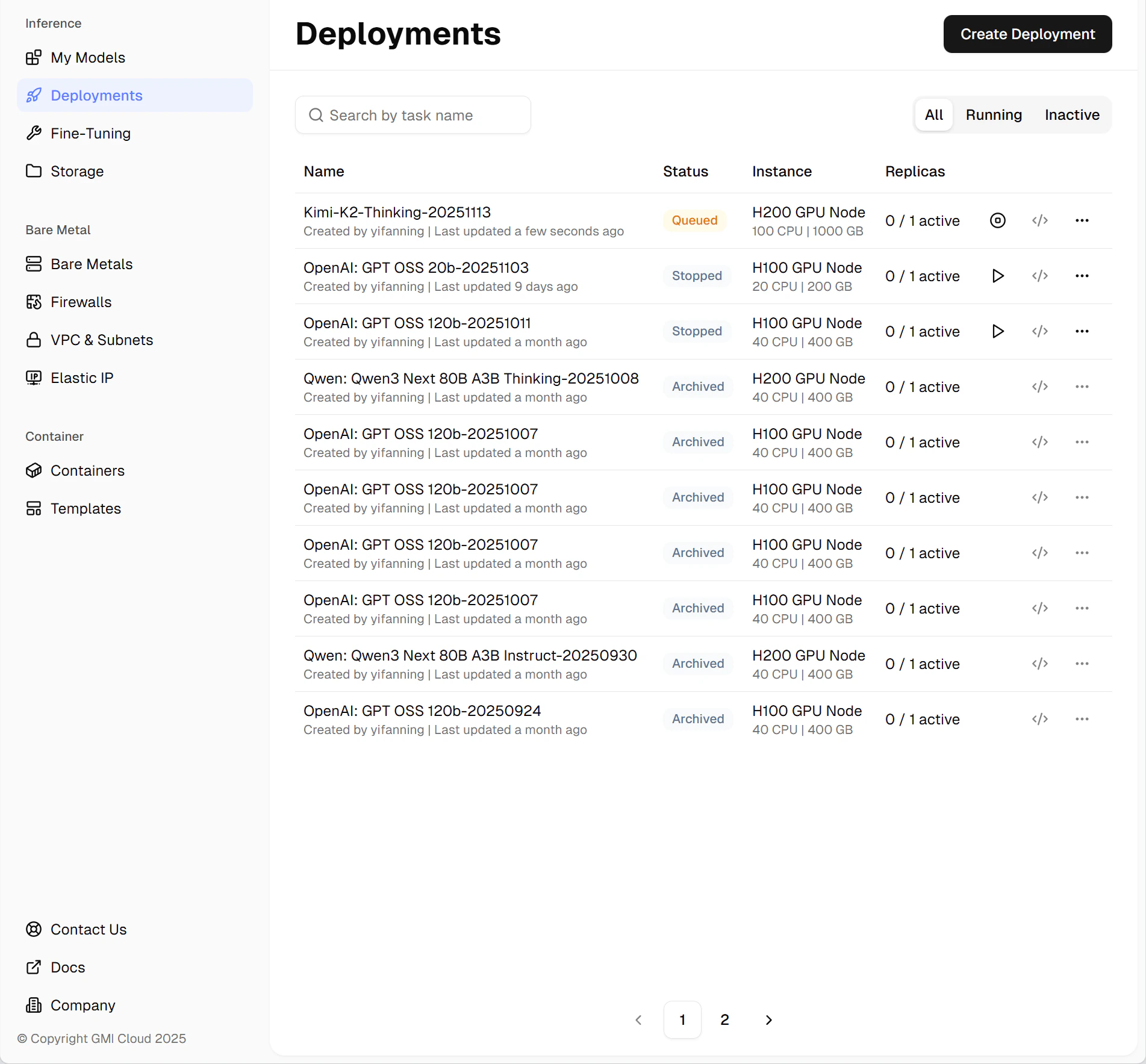
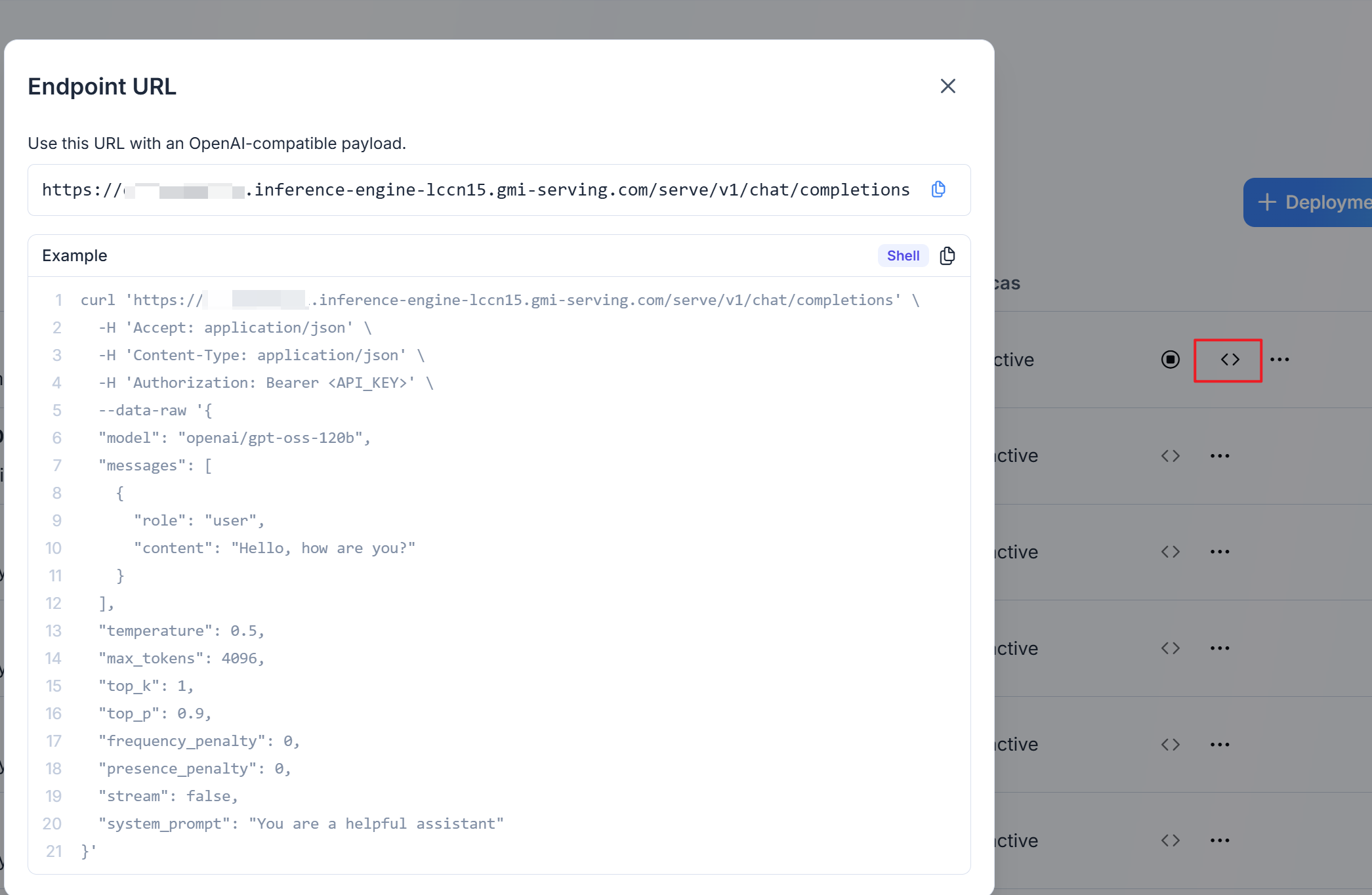
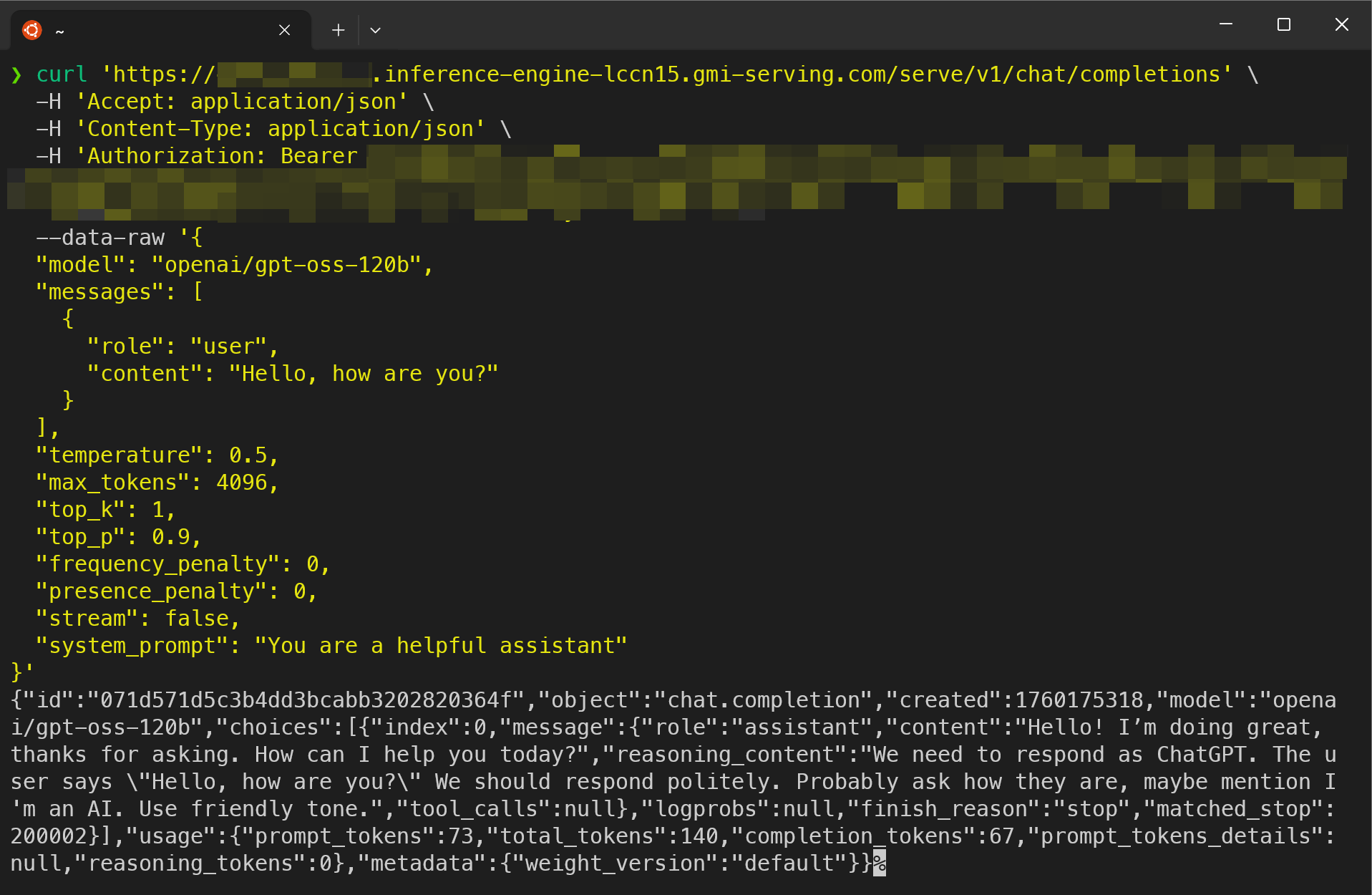
Invoke API Endpoint
Once deployment is in “Running” status, click the ”<>” symol to access endpoint URL: